

SHREC 2013 - Large Scale Sketch-Based 3D Shape Retrieval
Call For Participation
SHREC 2013 - Large Scale Sketch-Based 3D Shape Retrieval
Objective
The objective of this track is to evaluate the performance of different sketch-based 3D model retrieval algorithms using a large scale hand-drawn sketch query dataset for querying from a generic 3D model dataset.
Introduction
Sketch-based 3D model retrieval is focusing on retrieving relevant 3D models using sketch(es) as input. This scheme is intuitive and convenient for users to learn and search for 3D models. It is also popular and important for related applications such as sketch-based modeling and recognition, as well as 3D animation production via 3D reconstruction of a scene of 2D storyboard [1].
However, most existing 3D model retrieval algorithms target the Query-by-Model framework which uses existing 3D models as queries. Much less research work has been done regarding the Query-by-Sketch framework. Previous work on sketch-based 3D object retrieval has evaluated sketch-based retrieval on rather small benchmarks and compared against a limited number of methods. The most recent sketch-based retrieval evaluations have been demonstrated in [2] and [4]. The latter provided the until now largest benchmark data set, based on the Princeton Shape Benchmark (PSB) [5] with one user sketch for each PSB model. However, until now no comparative evaluation has been done on a very large scale sketch-based 3D shape retrieval benchmark. Considering of this and encouraged by the successful sketch-based 3D model retrieval track in SHREC'12 [2], we organize this track to further foster this challenging research area by building a very large scale benchmark and soliciting retrieval results from current state-of-the-art retrieval methods for comparison. We will also provide corresponding evaluation code for computing a set of performance metrics similar to those used in the Query-by-Model retrieval technique.
Benchmark Overview
Our very large scale sketch-based 3D model retrieval benchmark is motivated by a latest large collection of human sketches built by Eitz et al. [3]. To explore how humans draw sketches and human sketch recognition, they collected 20,000 human-drawn sketches, categorized into 250 classes, each with 80 sketches. This sketch dataset is regarded exhaustive in terms of the number of object categories. Furthermore, it represents a basis for a benchmark which can provide an equal and sufficiently large number of query objects per class, avoiding query class bias. In addition, the sketch variation within each class is high. Thus, we believe a new sketch-based 3D model retrieval benchmark built on [3] and the PSB can foster the research of sketch-based 3D object retrieval methods. This benchmark presents a natural extension of the benchmark proposed in [4] for very large scale 3D sketch-based retrieval.
PSB is the most well-known and frequently used 3D shape benchmark and it also covers most commonly occurring objects. It contains two datasets: "test" and "train", each has 907 models, categorized into 97 and 90 distinct classes, respectively. However, PSB has quite different numbers of models for different classes, which is a bias for retrieval performance evaluation. For example, in the "test" dataset the "fighter_jet" class has 50 models while the "ant" class only has 5 models. In [4] the query sketch dataset and the target model dataset share the same distribution in terms of number of models in each class.
Considering the above fact and analysis, we build the benchmark by finding common classes in both the sketch [3] and the 3D model [5] datasets. We search for the relevant 3D models (or classes) in PSB and the acceptance criterion is as follows: for each class in the sketch dataset, if we can find the relevant models and classes in PSB, we keep both the sketches and models, otherwise we ignore both. Totally, 90 of the 250 classes, thus 7200 sketches, in the sketch dataset have 1258 relevant models in PSB. The benchmark is therefore composed of 7200 sketches and 1258 models, divided into 90 classes. Fig. 1 shows example sketches and their relevant models of 18 classes in the benchmark. We randomly select 50 sketches from each class for training and use the remained 30 sketches per class for testing, while the 1258 relevant models as a whole are remained as the target dataset. Participants need to submit results on the training and testing datasets, respectively. To provide a complete reference for the future users of our benchmark, we will evaluate the participating algorithms on both the testing dataset (30 sketches per class, totally 2700 sketches) and the complete benchmark (80 sketches per class, 7200 sketches).
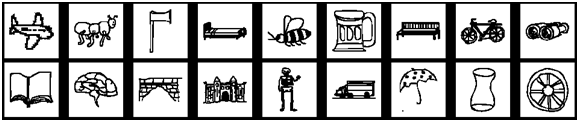

2D Sketch Dataset
The 2D sketch query set comprises the selected 7200 sketches (90 classes, each with 80 sketches), which have relevant models in PSB [5], from Eitz et al.'s [3] human sketch recognition dataset. One example indicating the variations within same class is demonstrated in Fig. 2.
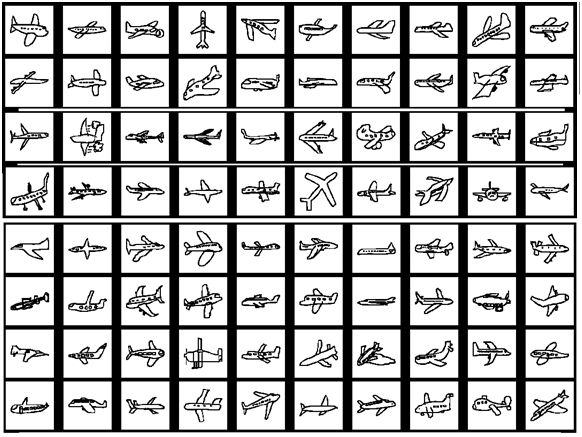
3D Model Dataset
The 3D benchmark dataset is built on the Princeton Shape Benchmark (PSB) dataset [5] which totally has 1814 models, subdivided into "train" and "test" datasets, each with 907 models and categorized into 97 and 90 classes respectively. But most of the 97 and 90 classes share the same categories with each other. Finally, 1258 models of 90 classes are selected to form the target 3D model dataset.
The Ground Truth
All the sketches and models are already categorized according to the classifications in Eitz et al. [3] and the PSB benchmark, respectively. In our classification and evaluation, we adopt the class names in Eitz et al. [3].
Evaluation Method
To have a comprehensive evaluation of the retrieval algorithm, we employ seven commonly adopted performance metrics in 3D model retrieval technique. They are Precision-Recall (PR) diagram, Nearest Neighbor (NN), First Tier (FT), Second Tier (ST), E-Measures (E), Discounted Cumulated Gain (DCG) and Average Precision (AP). We also have developed the code to compute them.
The Procedural Aspects
The test dataset will be made available on the 24th of January and the results will be due two weeks after that. Every participant will perform the queries and send us their retrieval results. We will then do the performance assessment. Participants and organizers will write a joint contest report to detail the results. Results of the track will be presented during the 3DOR workshop 2013 in Girona, Spain.
Procedure
The following list is a step-by-step description of the activities:
- The participants must register by sending a message to sketch@nist.gov and Bo Li. Early registration is encouraged, so that we get an impression of the number of participants at an early stage.
- The database will be made available via this website. Dataset.
- Participants will submit the dissimilarity matrix (also named as distance matrix) for both training and testing datasets. Up to 5 matrices, either for the training or testing datasets, per group may be submitted, resulting from different runs. Each run may be a different algorithm, or a different parameter setting. More information on the dissimilarity matrix file format. More information on the dissimilarity matrix file format.
- The evaluations will be done automatically.
- The organization will release the evaluation scores of all the runs.
- The participants write a one page description of their method with at most two figures and send their comments on the evaluation results.
- The track results are combined into a joint paper, published in the proceedings of the Eurographics Workshop on 3D Object Retrieval.
- The description of the tracks and their results are presented at the Eurographics Workshop on 3D Object Retrieval (May 11, 2013).
Schedule
| January 14 | - Provision of the benchmark data and specification of the file format by which results need to be submitted. |
| January 21 | - Few sample sketches and all the target models will be available on line. |
| January 31 | - Please register before this date. |
| February 1 | - Distribution of the training database. Participants can start the retrieval or train their algorithms. |
| February 10 |
- Submission of the results on the training dataset.
- Distribution of the testing database. Participants run their algorithms on the testing data. |
| February 16 (Extended) | - Submission the results on the testing dataset and a one page description of their method(s). |
| February 21 | - Distribution of relevance judgments and evaluation scores. |
| February 28 | - Track is finished, and results are ready for inclusion in a track report. |
| March 5 | - Submit the track paper for review. |
| March 25 | - All reviews due, feedback and notifications. |
| March 29 | - Camera ready track paper submitted for inclusion in the proceedings. |
| May 11 | - Eurographics Workshop on 3D Object Retrieval including SHREC'2013. |
Organizers
Bo Li, Yijuan Lu - Texas State University, USA
Afzal Godil - National Institute of Standards and Technology, USA
Tobias Schreck - University of Konstanz, Germany
Acknowledgement
We would like to thank Mathias Eitz, James Hays and Marc Alexa who collected the sketches.
We would also like to thank Philip Shilane, Patrick Min, Michael M. Kazhdan, Thomas A. Funkhouser who built the Princeton Shape Benchmark.
Note: Approval for the usage of the above data for the track has been obtained.
References
[1] Anh-PhuongTa, ChristianWolf, Guillaume Lavoue, and Atilla Baskurt, 3D object detection and viewpoint selection in sketch images using local patch-based Zernike moments, in CBMI, 2009, pp. 189-194
[2] Bo Li, Tobias Schreck, Afzal Godil, Marc Alexa, Tamy Boubekeur, Benjamin Bustos, J. Chen, Mathias Eitz, Takahiko Furuya, Kristian Hildebrand, S. Huang, Henry Johan, Arjan Kuijper, Ryutarou Ohbuchi, Ronald Richter, Jose M. Saavedra, Maximilian Scherer, Tomohiro Yanagimachi, Gang-Joon Yoon, and Sang Min Yoon, SHREC'12 track: Sketch-based 3D shape retrieval, in 3DOR, 2012, pp. 109-118
[3] Mathias Eitz, James Hays, Marc Alexa, How do humans sketch objects? ACM Trans. Graph. 31(4): 44, 2012
[4] Mathias Eitz, Ronald Richter, Tamy Boubekeur, Kristian Hildebrand, Marc Alexa, Sketch-based shape retrieval, ACM Trans. Graph. 31(4): 31, 2012
[5] Philip Shilane, Patrick Min, Michael M. Kazhdan, Thomas A. Funkhouser, The Princeton Shape Benchmark, SMI 2004, pp. 167-178, 2004
Please cite the papers:
[1] B. Li, Y. Lu, Afzal Godil, Tobias Schreck, Masaki Aono, Henry Johan, Jose M. Saavedra, S. Tashiro, In: S. Biasotti, I. Pratikakis, U. Castellani, T. Schreck, A. Godil, and R. Veltkamp (eds.), SHREC'13 Track: Large Scale Sketch-Based 3D Shape Retrieval, Eurographics Workshop on 3D Object Retrieval 2013 (3DOR 2013): 89-96, 2013.
[2] B. Li, Y. Lu, A. Godil, T. Schreck, B. Bustos, A. Ferreira, T. Furuya, M.J. Fonseca, H. Johan, T. Matsuda, R. Ohbuchi, P.B. Pascoal, J.M. Saavedra, A comparison of methods for sketch-based 3D shape retrieval, Computer Vision and Image Understanding (2013), doi: http://dx.doi.org/10.1016/j.cviu.2013.11.008.